1. Tổng quan về bộ nhớ ngắn hạn và dài hạn trong tác nhân LLM
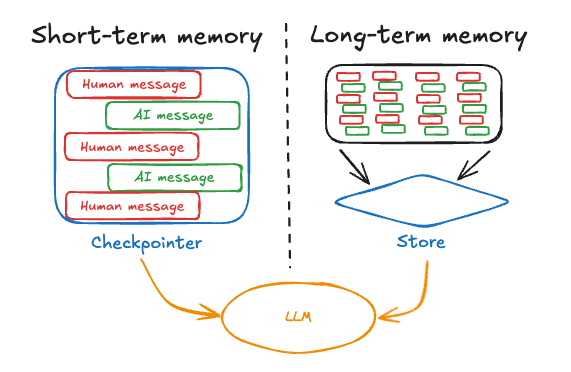
- Bộ nhớ ngắn hạn (Short-Term Memory - STM) trong ngữ cảnh LLM thường được hiểu là phần ngữ cảnh hiện hành mà mô hình có thể “nhớ” trong khi xử lý một tác vụ hoặc hội thoại medium.com redis.io. Nói cách khác, STM chính là cửa sổ ngữ cảnh (context window) của mô hình. Đặc điểm của bộ nhớ ngắn hạn là tính tạm thời và giới hạn: nội dung hội thoại gần nhất hoặc dữ liệu vừa cung cấp sẽ nằm trong STM, nhưng mô hình không thể nhớ mãi mọi thứ vượt quá kích thước cửa sổ ngữ cảnh của nó. Khi cuộc hội thoại kéo dài hoặc thông tin tích lũy nhiều, ta buộc phải bỏ bớt hoặc tóm tắt những phần cũ nếu không mô hình sẽ bị quá tải ngữ cảnh. Quan trọng là, STM mang tính tích lũy nhưng không bền – mô hình không có cơ chế tự loại bỏ hay cập nhật phần ngữ cảnh đã cung cấp; và sau khi phiên tương tác hiện tại kết thúc, toàn bộ STM cũng mất đi medium.com (tương tự như RAM của máy tính sẽ xóa dữ liệu khi tắt nguồn).
- Bộ nhớ dài hạn (Long-Term Memory - LTM) là cơ chế bổ sung nhằm khắc phục giới hạn trên của STM medium.com. Bộ nhớ dài hạn lưu trữ thông tin một cách bền vững và qua nhiều phiên làm việc – tức là những kiến thức, sự kiện quan trọng, hay kinh nghiệm rút ra được từ các tác vụ trước có thể được ghi lại để dùng cho tương lai medium.com. Nếu ví STM là RAM thì LTM giống như ổ cứng: dung lượng lớn và dữ liệu lưu lại giữa các phiên làm việc redis.io. Nhờ LTM, một tác nhân LLM có khả năng học từ trải nghiệm mà không cần train lại model. Chẳng hạn, agent có thể ghi nhớ phản hồi của người dùng hoặc kết quả thực thi code lần trước, để lần sau gặp tình huống tương tự sẽ xử lý tốt hơn medium.com. Việc này tương tự như con người viết nhật ký hay tài liệu: chúng ta lưu lại thông tin quan trọng để tra cứu về sau medium.com. LTM giúp agent dần hoàn thiện qua mỗi tương tác – đây là cách học mới dựa trên ngôn ngữ (ghi nhớ kiến thức) thay vì phải điều chỉnh trọng số mô hình như học tăng cường truyền thống medium.com medium.com.
- Sự kết hợp của STM và LTM là cần thiết để tác nhân LLM hoạt động hiệu quả. STM giúp agent duy trì mạch hội thoại và trạng thái hiện tại, còn LTM đảm bảo agent không “quên” các thông tin quan trọng qua thời gian skymod.tech. Thiếu STM, agent sẽ mất phương hướng chỉ sau vài lượt tương tác; thiếu LTM, agent sẽ lặp lại lỗi cũ hoặc quên mất ngữ cảnh dài hạn (ví dụ quên nội dung đầu của văn bản dài khi đã vượt quá cửa sổ ngữ cảnh) skymod.tech.
Ví dụ minh họa: Hãy hình dung một trợ lý ảo LLM giúp người dùng quản lý lịch làm việc. Bộ nhớ ngắn hạn cho phép nó hiểu câu hỏi hiện tại của người dùng và những tin nhắn trao đổi gần nhất (ví dụ: người dùng vừa nói "Lần tới tôi rảnh vào chiều thứ Sáu"). Bộ nhớ dài hạn cho phép trợ lý nhớ được thông tin nền quan trọng từ trước đó, chẳng hạn sở thích lịch trình của người dùng, các cuộc hẹn đã đặt từ tuần trước, hay thậm chí thói quen (ví dụ: người dùng thích họp vào buổi sáng) redis.io. Nhờ STM, trợ lý phản hồi mạch lạc trong ngữ cảnh hiện tại; nhờ LTM, trợ lý có thể chủ động nhắc nhở “Bạn thường không họp sau 5h chiều thứ Sáu, bạn có muốn giữ lịch trống không?” dựa trên dữ liệu tích lũy từ các phiên trước.
2. Kiến trúc tích hợp bộ nhớ vào pipeline của tác nhân LLM
- Một tác nhân LLM thường được tổ chức theo vòng lặp nhận thức-hành động: Nhận đầu vào → Xử lý (suy nghĩ & lên kế hoạch) → Hành động (gọi công cụ, truy xuất thông tin) → Cập nhật ngữ cảnh → Trả lời. Bộ nhớ được tích hợp vào vòng lặp này nhằm cung cấp ngữ cảnh cần thiết cho mỗi bước và lưu lại những gì quan trọng sau mỗi hành động skymod.tech skymod.tech.
- Mô hình kiến trúc một tác nhân LLM với bộ nhớ: Agent nhận input từ người dùng, sử dụng bộ nhớ ngắn hạn (context recent) để hiểu ngữ cảnh hiện tại, đồng thời truy vấn bộ nhớ dài hạn (thông qua kho dữ liệu vectơ) để lấy ra thông tin liên quan đã lưu trước đó. Sau bước suy nghĩ và lập kế hoạch (LLM Thought/Action), agent có thể gọi các công cụ (ví dụ: công cụ “RecallMemory” để tìm thông tin, hoặc “StoreMemory” để lưu thông tin mới). Kết quả truy xuất từ bộ nhớ (nếu có) sẽ được đưa vào ngữ cảnh cho lần gọi LLM kế tiếp. Cuối cùng, agent tổng hợp và trả về phản hồi cho người dùng.
- Trong kiến trúc trên, bộ nhớ ngắn hạn được duy trì dưới dạng lịch sử hội thoại hoặc trạng thái tạm thời trong mỗi phiên tương tác. Thông thường, ta lưu mọi tin nhắn hoặc chỉ một cửa sổ gồm N thông điệp gần nhất, rồi đính kèm chúng vào prompt mỗi khi gọi LLM.
- Ngược lại, bộ nhớ dài hạn được triển khai như một kho dữ liệu bên ngoài để lưu trữ thông tin vượt quá phạm vi phiên hiện tại skymod.tech. Mỗi khi cần nhớ lại kiến thức cũ hoặc dữ kiện từ các phiên trước, agent sẽ truy vấn kho LTM này. Có hai cách tích hợp LTM phổ biến trong pipeline: (1) Nhúng vào prompt – tức là lập trình agent tự động lấy các thông tin phù hợp từ LTM rồi chèn vào prompt đầu vào cho LLM; hoặc (2) Thông qua công cụ – tức là xem bộ nhớ như một “tool” mà agent có thể gọi đến trong quá trình suy luận skymod.tech. Ví dụ, với prompt kiểu ReAct, LLM có thể tạo ra chuỗi Thought: “Có thông tin quan trọng X không? -> Action:
search_memory("X")” để agent thực thi việc tìm kiếm trong LTM skymod.tech skymod.tech. Sau khi truy xuất, dữ liệu kết quả sẽ được đưa vào vòng lặp như một quan sát mới để LLM sử dụng ở bước suy nghĩ kế tiếp skymod.tech. - Quy trình tích hợp STM và LTM cho mỗi lượt tương tác của agent có thể diễn ra như sau:
- Nhận đầu vào người dùng: Agent tiếp nhận câu hỏi hoặc mệnh lệnh mới. Ví dụ: “Hôm nay là sinh nhật tôi, anh có gợi ý gì không?”.
- Truy vấn bộ nhớ dài hạn (tùy chọn): Trước khi trả lời, agent sẽ tìm kiếm trong LTM xem có dữ kiện nào liên quan. Trong ví dụ trên, agent có thể tìm hồ sơ người dùng trong LTM để xem tên và sở thích của người dùng, hoặc kiểm tra lịch sử hội thoại trước đây xem lần trước sinh nhật người dùng agent đã gợi ý gì.
- Tạo ngữ cảnh cho LLM: Agent xây dựng prompt cho mô hình LLM, bao gồm: (a) hướng dẫn hệ thống (định nghĩa vai trò agent và công cụ có sẵn), (b) lịch sử hội thoại gần đây (STM), và (c) các thông tin truy xuất được từ LTM (nếu có). Nhờ đó, LLM nhận đầy đủ ngữ cảnh hiện tại và kiến thức quá khứ liên quan để suy luận.
- LLM suy nghĩ và hành động: LLM sinh ra phản hồi. Nếu sử dụng phương pháp tư duy-hành động (vd ReAct), LLM có thể trả về bước Action yêu cầu gọi một công cụ. Thí dụ, LLM có thể quyết định gọi tool
LookupRecipenếu người dùng hỏi về món ăn, hoặc toolStoreMemoryđể lưu lại sự kiện “ngày sinh nhật đã được chúc mừng” vào LTM sau khi phản hồi. - Thực thi hành động (nếu có) và cập nhật bộ nhớ: Nếu có hành động như truy vấn thêm thông tin, agent sẽ thực thi (vd: gọi API tìm kiếm hoặc truy vấn vector DB). Kết quả thu được sẽ được bổ sung vào ngữ cảnh và loop quay lại bước 3 cho LLM xử lý tiếp. Nếu hành động là lưu vào bộ nhớ, agent sẽ ghi dữ liệu mới vào kho LTM (ví dụ: thêm “user A sinh nhật 20/7, thích bánh chocolate” vào database).
- Trả lời người dùng: Khi LLM đã tạo phản hồi cuối cùng (không yêu cầu action tiếp), agent gửi câu trả lời đó đến người dùng. Vòng lặp cho yêu cầu này kết thúc.
Trong suốt quy trình trên, bộ nhớ ngắn hạn đảm bảo agent hiểu đúng ngữ cảnh hiện tại (các bước 1 và 3), còn bộ nhớ dài hạn đảm bảo agent không bỏ sót kiến thức tích lũy trước đó (bước 2 và 5)
3. Công nghệ, dịch vụ và công cụ triển khai bộ nhớ
Để triển khai bộ nhớ cho tác nhân LLM, nhóm kỹ sư có thể sử dụng nhiều công nghệ và công cụ sẵn có, ưu tiên các giải pháp open-source hoặc dịch vụ cloud đơn giản. Dưới đây là một số lựa chọn tiêu biểu và đặc điểm của chúng:
- ChromaDB: Cơ sở dữ liệu vectơ mã nguồn mở, thiết kế chuyên cho ứng dụng AI. Chroma cho phép lưu trữ các embedding (biểu diễn vector của văn bản) kèm metadata và hỗ trợ truy vấn vector search hiệu quả trychroma.com.
- Redis (Redis Stack): Redis là cơ sở dữ liệu in-memory nổi tiếng với hiệu năng cực cao (đọc/ghi độ trễ microsecond) redis.io. Phiên bản Redis Stack (hoặc module Redis Vector Similarity) bổ sung khả năng lưu trữ vector embeddings và tìm kiếm xấp xỉ gần đúng trên vectơ. Redis đặc biệt thích hợp cho bộ nhớ ngắn hạn cần tốc độ (vd lưu trạng thái phiên, kết quả trung gian) cũng như bộ nhớ dài hạn cỡ vừa cần truy vấn nhanh redis.ioredis.io.
- FAISS: FAISS (Facebook AI Similarity Search) là thư viện mã nguồn mở tối ưu cho tìm kiếm tương đồng trên tập vector lớn en.wikipedia.org. Thư viện này cung cấp nhiều thuật toán indexing (IVF, HNSW, PQ...) giúp tìm vector gần nhất nhanh chóng, kể cả khi dữ liệu hàng triệu điểm. FAISS thường được dùng ở mức thư viện nhúng trong ứng dụng: ví dụ một pipeline Python có thể sử dụng FAISS để tạo index trên bộ embedding và query top-k tương tự mỗi khi cần.
- Pinecone (bản miễn phí): Pinecone là dịch vụ vector database trên mây, cung cấp API để lưu và truy vấn vector với cơ sở hạ tầng đã tối ưu. Pinecone bản miễn phí giới hạn dung lượng (thường vài nghìn vector) nhưng rất tiện để bắt đầu vì không phải tự quản trị máy chủ.
Ngoài các cái tên trên, hệ sinh thái vector database còn nhiều lựa chọn khác (Milvus, Qdrant, ElasticSearch + vector plugin, etc.) và các dịch vụ managed ( như Weaviate Cloud, Atlas Vector Search của MongoDB v.v.). Tuy nhiên với nhóm nhỏ, các giải pháp nêu trên đủ để đáp ứng hầu hết nhu cầu cơ bản: Chroma/FAISS cho open-source dễ tùy biến, Redis cho tốc độ cao nếu cần caching, SQLite cho lưu trữ đơn giản, và Pinecone cho phương án “plug and play” trên cloud.
4. Các pattern phổ biến trong triển khai bộ nhớ cho LLM
Khi thiết kế bộ nhớ ngắn hạn/dài hạn cho tác nhân LLM, có một số mô hình (pattern) phổ biến thường được kết hợp. Mỗi pattern giải quyết một khía cạnh giới hạn của trí nhớ LLM, và thường người ta dùng kết hợp nhiều pattern để đạt hiệu quả tối ưu redis.io. Dưới đây là các pattern tiêu biểu:
- Context Window (Cửa sổ ngữ cảnh): Đây là pattern cơ bản nhất, tận dụng trực tiếp cửa sổ ngữ cảnh tối đa của LLM làm bộ nhớ ngắn hạn. Tất cả thông tin cần thiết (prompt hệ thống, lịch sử hội thoại, dữ kiện bổ sung) đều được đóng gói trong input gửi vào mô hình.
- Conversation Buffer Memory (Bộ nhớ đệm hội thoại): Pattern này mở rộng từ context window, bằng cách lưu toàn bộ lịch sử hội thoại và cung cấp nó cho mô hình ở mỗi lượt tương tác. Cách đơn giản nhất là nối tất cả prompt/response trước đó vào trước câu hỏi hiện tại (giống như chatbot GPT lưu cả cuộc trò chuyện).
- Summarization (Tóm tắt bộ nhớ): Đây là pattern xử lý khi buffer memory trở nên quá tải. Thay vì giữ nguyên toàn bộ nội dung cũ, ta dùng chính LLM (hoặc mô hình tóm tắt) để tóm tắt những phần hội thoại cũ thành một đoạn tóm lược ngắn gọn, súc tích redis.io. Bản tóm tắt này sau đó được đưa vào ngữ cảnh (thay cho các đoạn chi tiết), giúp giảm lượng token nhưng vẫn giữ lại ý chính của cuộc trò chuyện trước đó. Có thể thực hiện tóm tắt liên tục: mỗi khi sắp vượt ngưỡng token, gộp phần cũ thành summary rồi lưu summary đó như một message trong lịch sử (tiếp tục lặp lại khi cần) jit.io.
- Semantic Chunking & Vector Retrieval (Phân chia ngữ nghĩa & truy vấn vectơ): Đây là pattern nền tảng cho bộ nhớ dài hạn kiểu RAG (Retrieval-Augmented Generation). Thay vì lưu trữ và truy xuất thông tin dựa trên từ khóa hay vị trí, ta phân chia thông tin thành các mảnh “chunk” có ý nghĩa (ví dụ mỗi đoạn văn, mỗi câu trả lời hoàn chỉnh) redis.io, sau đó vector hóa chúng thành embedding và lưu vào vector database. Khi cần truy xuất, agent sẽ chuyển truy vấn hiện tại thành embedding rồi tìm trong kho vectơ những chunk có độ tương đồng ngữ nghĩa cao nhất medium.com.
- Knowledge Graph / Memory Graph (Đồ thị tri thức): Đây là pattern nâng cao, trong đó ký ức của agent được lưu dưới dạng đồ thị các thực thể và mối quan hệ thay vì những đoạn văn bản rời rạc. Ý tưởng chính: trích xuất thông tin thành các cặp node-edge (ví dụ: Alice -[là sếp của]-> Bob, hoặc Sự kiện X -[thời gian]-> ngày Y) tạo thành một graph có cấu trúc redis.io. Mỗi khi cần nhớ lại hoặc suy luận, agent có thể truy vấn đồ thị này (tương tự cơ sở tri thức) để lấy các mắt xích liên hệ logic.
- Memory Consolidation (Củng cố ký ức): Đây không hẳn là một pattern riêng lẻ mà là một quá trình hỗ trợ, lấy cảm hứng từ quá trình ngủ/ghi nhớ dài hạn của con người. Ý tưởng là thỉnh thoảng agent sẽ duyệt lại ký ức, xác định những thông tin quan trọng và tổ chức lại bộ nhớ cho tối ưu. Ví dụ, sau mỗi phiên, agent có thể tổng kết lại những gì học được (sử dụng summarization hoặc extraction) và lưu bản tổng kết vào LTM, đồng thời xóa hoặc giảm độ ưu tiên những chi tiết vụn vặt.
5. Kinh nghiệm triển khai thực tế: hiệu suất, độ trễ, lưu trữ và bảo mật
Thiết kế hệ thống bộ nhớ cho tác nhân LLM cần cân nhắc các đánh đổi (trade-offs) giữa hiệu năng, độ trễ, chi phí lưu trữ và yêu cầu bảo mật. Dưới đây là một số kinh nghiệm thực tế và lưu ý kỹ thuật liên quan:
- Hiệu suất & Độ trễ: Việc tích hợp bộ nhớ tất yếu thêm một số bước xử lý (truy xuất DB, tóm tắt LLM phụ trợ) nên sẽ ảnh hưởng đến độ trễ phản hồi. Tuy nhiên, nút thắt cổ chai thường nằm ở LLM hơn là ở truy vấn bộ nhớ. Thực tế cho thấy thời gian suy luận của mô hình (vài trăm ms đến vài giây tùy độ dài prompt) lớn hơn nhiều so với thời gian truy vấn vector DB (thường chỉ vài ms) milvus.io. Vì vậy, sử dụng vector search hay database tối ưu (như Redis, FAISS) thường không làm tăng đáng kể độ trễ tổng thể, miễn là triển khai hợp lý.
- Quản lý lưu trữ & quy mô dữ liệu: Một thách thức thực tế là bộ nhớ dài hạn có thể phình to rất nhanh. Mỗi phiên chat dài có thể sản sinh ra hàng ngàn token thông tin; nếu lưu tất cả mọi thứ, sau vài trăm người dùng hay vài tháng vận hành, kho LTM có thể chứa hàng triệu đoạn nhớ. Điều này ảnh hưởng đến chi phí lưu trữ (dung lượng ổ đĩa, bộ nhớ RAM cho index) và cả hiệu quả truy xuất (dù truy vấn vector nhanh, dataset quá lớn vẫn có thể giảm throughput khi scan nhiều) redis.io. Do đó, cần chiến lược lọc và quên: xác định loại thông tin nào cần lưu và mức chi tiết. Không phải mọi thứ người dùng nói đều đáng lưu. Ví dụ, thông tin định danh, sở thích, quyết định quan trọng nên lưu (có thể ở dạng cấu trúc), nhưng những câu chitchat xã giao có lẽ không cần. Triển khai có thể kết hợp memory score hay trọng số thời gian: gán độ ưu tiên cho mỗi memory và định kỳ xóa bỏ những memory quá cũ hoặc ít giá trị.
- Bảo mật & Riêng tư: Bộ nhớ của tác nhân LLM thường chứa dữ liệu nhạy cảm (ví dụ thông tin cá nhân người dùng, nhật ký trao đổi riêng tư, hoặc dữ liệu nội bộ doanh nghiệp). Vì vậy, vấn đề bảo mật cần được đặt lên hàng đầu khi triển khai.
6. Đề xuất khung triển khai đơn giản, hiệu quả cho nhóm kỹ sư nhỏ
Với một nhóm kỹ sư nhỏ (~5 người) và mục tiêu xây dựng tác nhân LLM có bộ nhớ, nên hướng đến một kiến trúc đơn giản mà hiệu quả, tận dụng tối đa công cụ có sẵn thay vì phát triển mọi thứ từ đầu. Dưới đây là khung đề xuất từng bước:
- Bắt đầu với bộ nhớ ngắn hạn cơ bản: Sử dụng ngay cơ chế buffer memory do các thư viện có sẵn cung cấp.
- Tích hợp tóm tắt cho hội thoại dài: Khi đã có buffer memory, triển khai thêm cơ chế summarization. Ví dụ: dùng chính mô hình LLM (ở chế độ nhiệt độ thấp, khuynh hướng tóm tắt) để định kỳ tóm tắt phần lịch sử cũ khi buffer vượt ngưỡng.
- Chọn giải pháp vector store cho bộ nhớ dài hạn: Song song STM, thiết lập một kho LTM dưới dạng vector database để lưu trữ thông tin cần nhớ lâu. Đối với nhóm nhỏ, ChromaDB là lựa chọn tốt nhờ dễ dùng và miễn phí trychroma.com.
- Sử dụng thông tin từ LTM trong vòng lặp agent: Sau khi có vector store, cần bổ sung logic cho agent để khai thác nó. Có hai cách:
- (a) Tự động truy vấn trước mỗi câu hỏi – ví dụ, mỗi lần user gửi câu hỏi, ta gọi vector DB tìm các memory liên quan (dựa trên embedding của câu hỏi + có thể kèm ngữ cảnh gần) rồi chèn những kết quả đó vào prompt, dưới dạng một phần “Memory” hoặc tài liệu tham khảo.
- (b) Cho phép agent gọi truy vấn qua function – tức là trong prompt hệ thống, liệt kê một function như
def recall(query)để LLM có thể quyết định gọi nếu cần thêm thông tin. - Cách (a) dễ thực hiện và đảm bảo luôn cung cấp trí nhớ cho LLM, thích hợp khi domain rõ ràng (ví dụ hỏi gì cũng nên tìm kiến thức nền). Cách (b) linh hoạt hơn, tránh truy vấn thừa khi không cần, nhưng phức tạp hơn vì đòi hỏi thiết kế prompt để LLM biết khi nào gọi hàm.
- Triển khai lưu trữ cấu trúc cho dữ liệu quan trọng: Ngoài vector store phục vụ tìm kiếm ngữ nghĩa, nhóm có thể thiết lập thêm một kho tri thức dạng cấu trúc (nhỏ) để lưu các thông tin cố định hoặc quan hệ chính. Ví dụ: một bảng SQLite hoặc JSON file lưu profile người dùng (tên, ngày sinh, sở thích), các quy tắc business, danh sách sự kiện đã xảy ra... Khi cần, agent có thể truy vấn trực tiếp (hoặc qua code) những dữ liệu này theo khóa (key lookup) thay vì phải tìm mù mờ qua vector.
- Đảm bảo an ninh và phân quyền dữ liệu: Ở bước đầu, khi kiến trúc còn đơn giản, các thành phần có thể chạy trên một máy chủ nên rủi ro chưa lớn. Tuy nhiên, ngay từ đầu nhóm nên thiết lập nguyên tắc bảo mật.
- Tận dụng thư viện và dịch vụ hỗ trợ: Với nhân lực giới hạn, việc tận dụng các giải pháp có sẵn là chiến lược thông minh. Hãy dùng LangChain hoặc LlamaIndex để tiết kiệm thời gian xây dựng pipeline.
- Kiểm thử và điều chỉnh dần dần: Bắt đầu với phạm vi nhỏ – ví dụ, triển khai agent nhớ được thông tin qua một phiên chat đơn, sau đó mở rộng để nhớ giữa các phiên. Kiểm thử với các tình huống cụ thể: agent có nhớ tên người dùng sau nhiều lượt không? Có nhớ được kiến thức đã cung cấp tuần trước không? Nếu phát hiện quên, xem lại pipeline (có lưu vào LTM không, có truy vấn lại đúng lúc không). Kiểm tra độ trễ: nếu mỗi câu trả lời mất quá lâu, xem bước nào chậm (tóm tắt có cần tối ưu không, có gọi vector search quá nhiều lần không).
- Ưu tiên đơn giản và rõ ràng: Nguyên tắc cuối cùng, với nguồn lực nhỏ, hãy chọn giải pháp dễ triển khai và bảo trì. Ví dụ, nếu team chưa ai rành về quản trị database lớn, thì dùng Chroma cục bộ thay vì cố cài Milvus cluster. Nếu chi phí là vấn đề, ưu tiên open-source trên máy có sẵn thay vì gọi API trả phí liên tục (có thể dùng model open-source để tạo embedding thay cho OpenAI API để giảm chi phí dài hạn).
Kết luận: Khung triển khai trên hướng đến một hệ thống bộ nhớ LLM "vừa đủ dùng" cho nhóm nhỏ – kết hợp conversation buffer để duy trì ngữ cảnh ngắn hạn, summarization để cô đọng thông tin cũ, vector database (Chroma/FAISS) cho trí nhớ dài hạn theo ngữ nghĩa, cùng với các biện pháp quản lý dữ liệu và bảo mật phù hợp. Cách tiếp cận này tận dụng các công cụ phổ biến và đã được cộng đồng kiểm chứng, giúp nhóm kỹ sư nhỏ nhanh chóng xây dựng được tác nhân LLM có khả năng nhớ và học hỏi, đồng thời có thể mở rộng và tinh chỉnh dễ dàng trong tương lai. Với một kiến trúc rõ ràng và linh hoạt, tác nhân của bạn sẽ không còn "não cá vàng" mà có thể ghi nhớ ngắn hạn lẫn dài hạn một cách hiệu quả, phục vụ tốt mục tiêu nghiệp vụ đề ra.